Bayesian Learning on the Candy Example
For the Bayesian learning, Professor Arindam Banerjee has a very good example of candy bages. In this post, we use the candy example to explain and summarize Bayesian learning. Related code can be found here.
Bayes Theorem
Before we reach out to Bayesian learning. We need first review the idea of Beyas Theorem.
\[p(\theta|\mathcal X)= \frac{p(\mathcal X|\theta)p(\theta)}{p(\mathcal X)}\]\(p(\theta)=\) prior probability of hypothesis \(\theta\)
\(p(\mathcal X)=\) prior probability of training data \(\mathcal X\)
\(p(\theta \mid \mathcal X)=\) posterior probability of \(\theta\) given data \(\mathcal X\)
\(p(\mathcal X \mid \theta)=\) probability of \(\mathcal X\) given \(\theta\)
Bayesian Estimation
Usually, we have more than one hypotheses and we want the most probable hypothesis given the training data. That is, Bayesian Estimation can help us choose an appropriate hypothesis from multiple hypotheses (in discrete hypothesis space), or compute the apporprate parameter (in continuous hypothesis space).
Maximum a posteriori (MAP), as its name suggests, is to estimate the parameter \(\theta\) by maximize the posteriori \(p(\theta \mid \mathcal X)\).
\[\begin{align} \theta_{\text{MAP}} &= \text{argmax}_\theta \phantom{2} p(\theta|\mathcal X) \\ &= \text{argmax}_\theta \phantom{2} \frac{p(\mathcal X|\theta)p(\theta)}{p(\mathcal X)} \\ &= \text{argmax}_\theta \phantom{2} p(\mathcal X|\theta)p(\theta) \end{align}\]Correspondingly, the Maximum Likelihood (ML) is as follows:
\[\theta_{\text{ML}} = \text{argmax}_\theta \phantom{2} p(\mathcal X|\theta)\]Basic Idea
According to Professor Banerjee, “The Bayesian view of learning is updating probability distribution over the hypothesis space.”
Here we use the following notations: \(H\) is the hypothesis variable, values \(h_1\), \(h_2\), …. \(P(h_i)\) is the prior. We can assume \(P(h_i)=P(h_j)\) when we have no further information about the prior.
Training data \(\mathcal X=\{x^1,x^2,...,x^N\}\)
Given data, each hypothesis has a posterior:
\[P(h_i|\mathcal X)=\alpha P(\mathcal X|h_i)P(h_i)\]For prediction, we can use a weighted average over all the hypotheses instead of picking the best-guess one:
\[P(x_\text{test}|\mathcal X)=\sum_i P(x_\text{test}|h_i)P(h_i|\mathcal X)\]The Candy Example
Suppose there are five kinds of bags of candies:
- 10% are \(h_1\): 100% cherry candies
- 20% are \(h_2\): 75% cherry candies + 25% lime candies
- 40% are \(h_3\): 50% cherry candies + 50% lime candies
- 20% are \(h_4\): 25% cherry candies + 75% lime candies
- 10% are \(h_5\): 100% lime candies
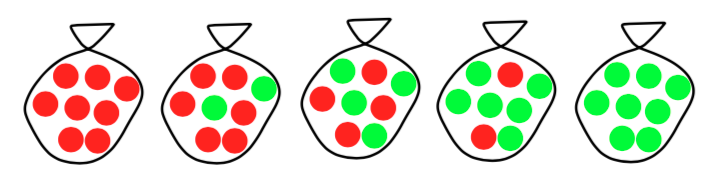
(The figure is taken from Prof. Banerjee’s slides)
We take one candy at each time and put the candy back. Then we have the following observations:

We need to answer two questions:
- What kind of bag is it?(Estimation)
- What flavor will the next candy be? (Prediction)
Estimation (Bayesian posterior updating)
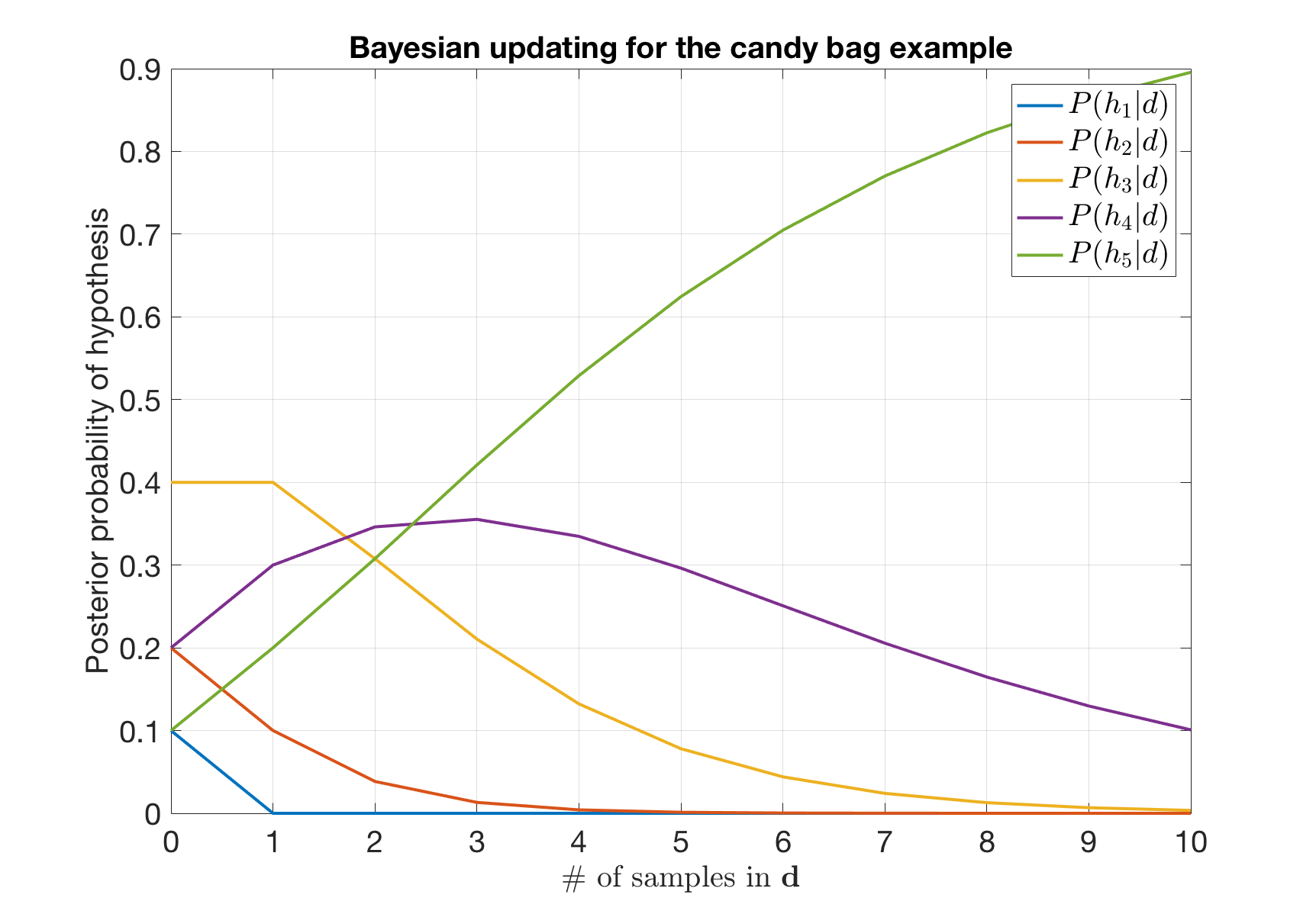
Here we compute the the posterior after each candy is drawn:
Before any candy is drawn, the posterior is the prior:
| # of candies drawn | \(p(h_1|d)\) | \(p(h_2|d)\) | \(p(h_3|d)\) | \(p(h_4|d)\) | \(p(h_5|d)\) |
|---|---|---|---|---|---|
| 0 | 0.1 | 0.2 | 0.4 | 0.2 | 0.1 |
After the first candy is drawn, we have:
\[p(d) = \sum_{i=1}^{5}p(h_i)p(d|h_i) = 0.1*0 + 0.2*0.25 + 0.4*0.5 + 0.2*0.75 + 0.1*1 = 0.5\] \[p(h_1|d) = \frac{p(d|h_1)p(h_1)}{p(d)} = \frac{0.1*0}{0.5} = 0\] \[p(h_2|d) = \frac{p(d|h_2)p(h_2)}{p(d)} = \frac{0.2*0.25}{0.5} = 0.1\] \[p(h_3|d) = \frac{p(d|h_3)p(h_3)}{p(d)} = \frac{0.4*0.5}{0.5} = 0.4\] \[p(h_4|d) = \frac{p(d|h_4)p(h_4)}{p(d)} = \frac{0.2*0.75}{0.5} = 0.3\] \[p(h_5|d) = \frac{p(d|h_5)p(h_5)}{p(d)} = \frac{0.1*1}{0.5} = 0.2\]That is:
| # of candies drawn | \(p(h_1|d)\) | \(p(h_2|d)\) | \(p(h_3|d)\) | \(p(h_4|d)\) | \(p(h_5|d)\) |
|---|---|---|---|---|---|
| 1 | 0 | 0.1 | 0.4 | 0.3 | 0.2 |
Similarly, we can have the following results:
| # of candies drawn | \(p(h_1|d)\) | \(p(h_2|d)\) | \(p(h_3|d)\) | \(p(h_4|d)\) | \(p(h_5|d)\) |
|---|---|---|---|---|---|
| 2 | 0 | 0.038 | 0.308 | 0.346 | 0.308 |
| 3 | 0 | 0.013 | 0.211 | 0.355 | 0.421 |
| 4 | 0 | 0.004 | 0.132 | 0.335 | 0.529 |
| 5 | 0 | 0.001 | 0.078 | 0.296 | 0.624 |
| 6 | 0 | 0.000 | 0.044 | 0.251 | 0.705 |
| 7 | 0 | 0.000 | 0.024 | 0.206 | 0.770 |
| 8 | 0 | 0.000 | 0.013 | 0.165 | 0.822 |
| 9 | 0 | 0.000 | 0.007 | 0.130 | 0.864 |
| 10 | 0 | 0.000 | 0.003 | 0.101 | 0.896 |
The updating process can be shown in the figure below:
Prediction
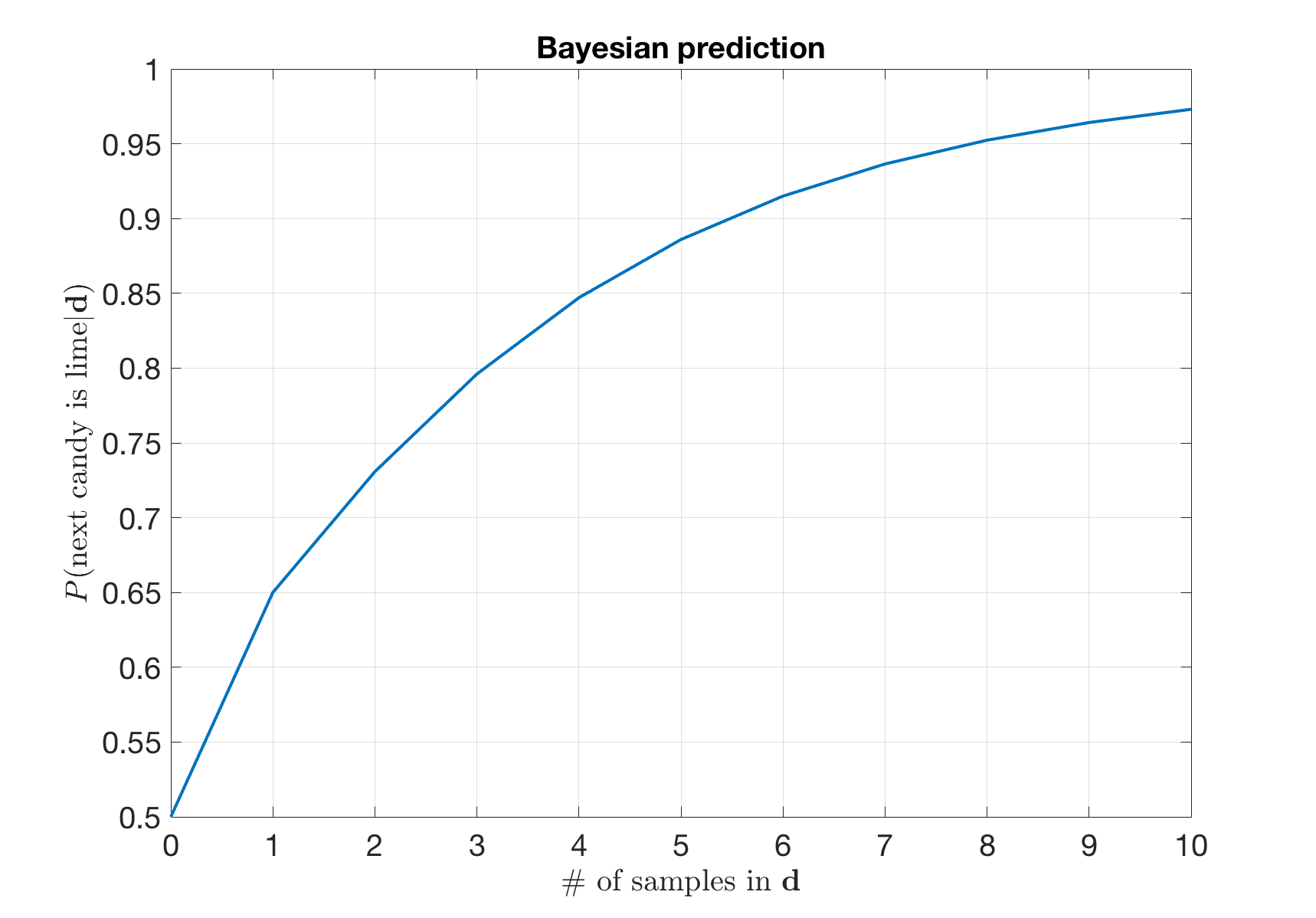
For prediction, we use a weighted average over all the hypotheses. Before any candy is drawn,
\[\begin{align} P(\text{next candy is lime} | \mathbf{d}) &= \sum_{i=1}^{5} P(\text{next candy is lime} | h_i) P(h_i|\mathbf{d}) \\ &= 0*0.1 + 0.25*0.2 + 0.5*0.4 + 0.75*0.2 + 1*0.1 = 0.5 \end{align}\]After the first lime candy is drawn, we have \(\begin{align} P(\text{next candy is lime} | \mathbf{d}) &= \sum_{i=1}^{5} P(\text{next candy is lime} | h_i) P(h_i|\mathbf{d}) \\ &= 0*0 + 0.25*0.1 + 0.5*0.4 + 0.75*0.3+ 1*0.2 = 0.65 \end{align}\)
Similarly, we have the following figure.